
I’ve been doing quite a bit of archival research since June. While digital cameras have made it much easier to create exact copies of the documents we see in the archive, managing those photos can be a challenge.
I decided that before I began amassing a lot of photographs that I would be using for the next few years, I would find a better way to capture the documents I saw. I opted for the app Scanbot 3.8 and paid $5 for the Pro version. Since June, I’ve used it in six different archives on all types of documents.
While it is not perfect for all the historian’s needs, and there are some circumstances when it isn’t the best tool, Scanbot is now my first choice for archival photographing. The main reason is that it lets me organize my photographs and save them in an easy-to-use, easy to find format, right as I am taking the pictures.
Scanbot turns your smartphone into a scanner. You hold the phone over the document, and it uses the phone’s camera to detect a document below. Based on what the phone sees, it draws a teal-colored rectangle around the edges of the document, more or less accurately.
Once it has detected the document and focused–both happen automatically–Scanbot takes a picture of the document. You don’t actually have to press a button to take the picture.
Scanbot also crops around what it thinks are the edges of the document. If you don’t like the way it was cropped, you can manually adjust the rectangle on the raw photograph.

You add more pictures to the file by repeating this process: swipe left to return to the camera, and take another picture of the next document.
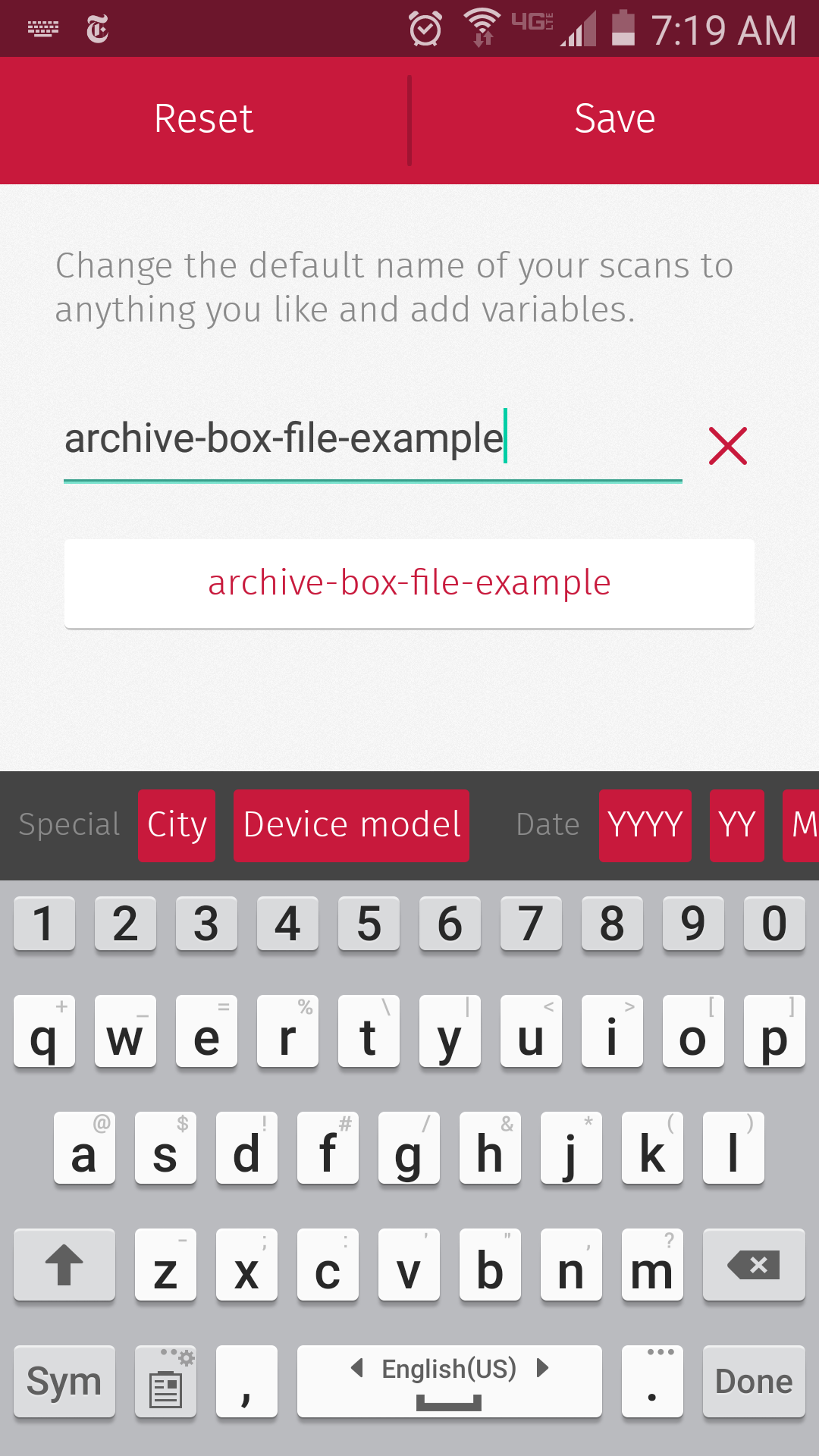
When you are finished, Scanbot will save the series of cropped images as a PDF and upload it to the folder you want in the cloud service of your choice and, if you’ve paid for the Pro version, the PDF will be named as you designate. My file names have the name of the archive, the box number, and the file number, and a short tag suggesting what the document is.
The app works best for capturing a flat document sitting on top of a surface in a contrasting color. Sometimes in the archive, those conditions are easy to achieve. But in many cases, we are not working with a clean piece of white paper on a dark wood desk, but rather with a messy stack of brown pages inside a brown folder.
In that situation, Scanbot still works, it just takes longer to detect the document and capture the image, and you need to fix the crop job more often.

When photographing pages in bound volumes or even long pamphlets that do not lie flat, I would not recommend using Scanbot at all. Scanbot sees curves, and not the straight lines that it uses to find the document. The app then struggles to detect the page, frantically flashing the alternating messages “Don’t move” and “Move closer.” Particularly frustrating (and also a little funny) is the error message “No document” that appears above, well, the document you are trying to photograph. For any bound materials, the point-and-shoot will be much faster than Scanbot.
Scanbot uses a lot of battery charge. You will need to bring your phone’s charger, or better yet, a spare battery and spare battery charger, to use it for a full day in the archive. I would recommend that you turn off the OCR feature (it makes the document upload too slowly) and frequently confirm that documents are actually uploading to the cloud.
Scanbot wasn’t designed for historians in the archive, and I am not ready to abandon my real camera completely. But it is about the same speed as using a regular camera thanks to the automated features. And since it is not costing me time in the archive, the other benefits of Scanbot are hard for me to pass up. It saves me from the tedious tasks of transferring images from an SD card to the computer, putting them in the appropriate folders, rotating them, and combining the images into PDFs. I suspect that the process of re-reading my materials, and writing the dissertation, will be just a little easier because of Scanbot.

[…] you may have guessed from my last post on archive tech, I am determined to make archival research as painless and efficient as […]
LikeLike
[…] This post is about where to stay and how to travel well on short research trips. To read my thoughts on how to plan the timing of research trips, read this. I talk more specifically about “surviving the archive” here. For ideas on how to photograph efficiently in the archive, try this post. […]
LikeLike
[…] goals. The previous posts were about scheduling trips and traveling well. I have also written about archive photography technology and archive survival […]
LikeLike